
Encoding headaches, emoticons, and R’s handling of UTF-8/16
I was recently asked for help from a colleague (@kmmunger) who was experiencing a choke on cleaning the tokenized texts from Twitter data. The tweets were in the JSON format that comes from the Twitter API, in what we thought was UTF-8 encoding. Turns out these tweets used some emoticons from the nosebleed section of the Unicode maps, and these were not being read properly into R, as quanteda was being used for processing this text.
The error message looked something like this:
Creating dfm from corpus ...
... indexing documents</span></p>
... tokenizing texts, found 2,426 total tokens</span></p>
... cleaning the tokens</span></p>
Error in tolower(x) : invalid input 'í ½í¸”' in 'utf8towcs'
The solution I proposed turned out to be tricky and ultimately, not very satisfactory. The problem seems to be built in to R and the way it handles byte-encoded Unicode text. The situation in essence: The tweet texts included emoji, which use a code point in Unicode that is pretty high up in the table. It’s so high, it seems, that the variable byte encoding used to represent the code point gets represented by two code “surrogates” in whatever source encoded them. Now you could say that this is a fault in whatever encoded the texts, and that’s probably now wrong, since R handled the emoji when entered directly as UTF-8 (see below). However it’s also clear that R tries to read each byte of the surrogate pair as a separate Unicode character, which produces an incorrect result. Because the lowercase operation is undefined for this incorrect result, the clean() function produces an error when it attempts the conversion to lowercase.
You can read more about surrogates here, but beware, you are starting down the rabbit hole.
To test this, I focused on a single tweet (but one of many) that was causing problem. In the plain text form, this was represented by Unicode escape characters. \u201c is an easy one: This is the left “curly quote”. It’s not until later in the text that the single character emoji are represented by a two-byte \uXXXX sequence. In plain text, it looked like this:
\u201c@AyeBeKnowin: No words \ud83d\ude14 RT @NinTANDO_Me: @AyeBeKnowin the Knicks .... Go ahead say suttin\u201d\ud83d\ude1e\ud83d\ude1e\ud83d\ude1e
My interpretation of what is happening: The text is plain ascii but with the non-ascii unicode character represented by their \uXXXX escape codes. For characters that R can handle, like curly quotes, this will be \u201c, a left curly quote, which is the first character in tweet 12. Additional characters exist as TWO unicode \uXXXX points, such as the \ud83d\ude14 which is actually the encoding using surrogates of a single unicode emoji character, with code point U+1F614. See http://apps.timwhitlock.info/emoji/tables/unicode.
Along the process of reading in the tweets and converting them to what R understands as UTF-8, it is converting this into the byte representation (in hexadecimal) as “\xed\xa0\xbd\xed\xb8\x94”, when it should in fact be “\xF0\x9F\x98\x94”. This works fine, as you can see if try in R:
> tolower("\xF0\x9F\x98\x94")</span></p>
<p class="p1"><span class="s1">[1] "\U0001f614"
it returns the unicode code point as \U without converting it. I am not sure why R chose this byte conversion, or indeed whether this is really an error or if there is something I have got wrong here.
The reason it’s encoded originally as “\ud83d\ude14” in the source file appears to be is because this is the surrogate representation, as you will see if you click on the link from the above page directly here: http://apps.timwhitlock.info/unicode/inspect/hex/1F614. It turns out that this character is the “pensive face” emoticon (see below for what this looks like). I qualify this statement because I am not an expert on Unicode encodings and certainly not on the surrogate byte “hack” that appears to have been one of the reasons UTF-16 is discouraged.
Laboring through the tweets, it was possible to check the byte representations in the input text using the tool from http://rishida.net/tools/conversion/. Pasting the first of the above tweets into the green box and hitting convert, the emoticon emerges. Note here again that the actual string with the \u escape codes is pure ASCII, but the byte encoding is contained in the \uXXXX sequences, which R converts (wrongly, apparently) into hex byte sequences represented as \xXX.
The short-term solution to this was to simply use iconv() in a way that eliminated the untranslateable multibyte codes. But this is hardly a solution, since it is discarding the emoticons that might make interesting textual features — especially here, since hte application related to sentiment analysis. But this will remove the offending characters, and make the call to clean() work fine:
iconv(tweets$text, "ASCII", "UTF-8", sub="")
I also suspect that the problem could be solved if the input text were in an actual UTF-8 encoding, rather than being in an ASCII formatted JSON file that represents non-ASCII characters as hexadecimal escape sequences. On my Mac’s R console, for instance, this worked and even displayed properly.
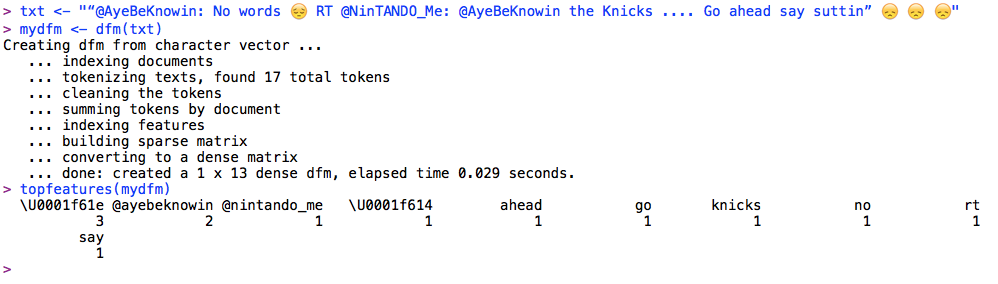
Here it does not display as ann emoticon in the output from topfeatures() but it does have the correct code point reference. R can display this on my output device using cat() but not using the default print method for a named character vector.
I would love to read comments from those with more experience with encoding than I have, since it’s quite possible I got some of the details wrong here.